Startup Experience
Recently I took part in a small startup.
Russian bred, so expect some vodka pictures here below.
I mainly played DevOps role, but as always in such cases everyone wears many hats.
We all learned a lot, and so I wanted to share some key insights.
Active phase described below happened within 1 month.
Idea
Desperation is the best driver to come out of comfort zone.
Pregnant wife in a passenger seat, tired brains after a day of work, busy streets with no space to park.
Ok, maybe I’m exaggerating a little… but the parking bit was true.
One of the founders was extremely annoyed every day looking for where to park his car, with all the official car parks full, but lots of private yards empty and abandoned in his home town.

Instead of doing what normal people do, ie going home and drinking beer,
he brewed some tee and decided to bridge the gap between land owners and car drivers.
And called his friends to join him…
Team
Old school mates, student hostel neighbours, fellow souls computer geeks… some random drinking buddies and beautiful strangers of opposite sex… ok, here I’m fantasizing again.
Some with ground level knowledge of electronic systems.
Some with cloud development experience.
And some with great marketing and business and startup understanding.
Hustlers, hackers, hipsters…
Overall 11 (!) people, with ~6 as a core team.
Mostly agreeing on the way to go, but sometimes not …

And a bit of investment promise from a couple of Accelerators…
And of course technology to help with all that.
Technologies
So we decided it must be a mobile … app … web … don’t know, we still argue about that.
Or maybe no app at all, but a camera with registration number recognition, and automatic barriers.
Key advantage
At this stage I grabbed my smartphone, and counted at least 6 such apps I’d been already using.
Fierce competition… or an opportunity?
Maybe it’s an advantage:
- give people just 1 app, that has access to all the various networks of parkings
- as well as direct agreements with private land owners
- and use technology to automate the hell out of it
How would you develop such a thing?
Architecture
You won’t be surprised when you look at the architecture, as it’s quite standard for these days.
“IT” is an industry now, not an art, not even a craftsmanship.
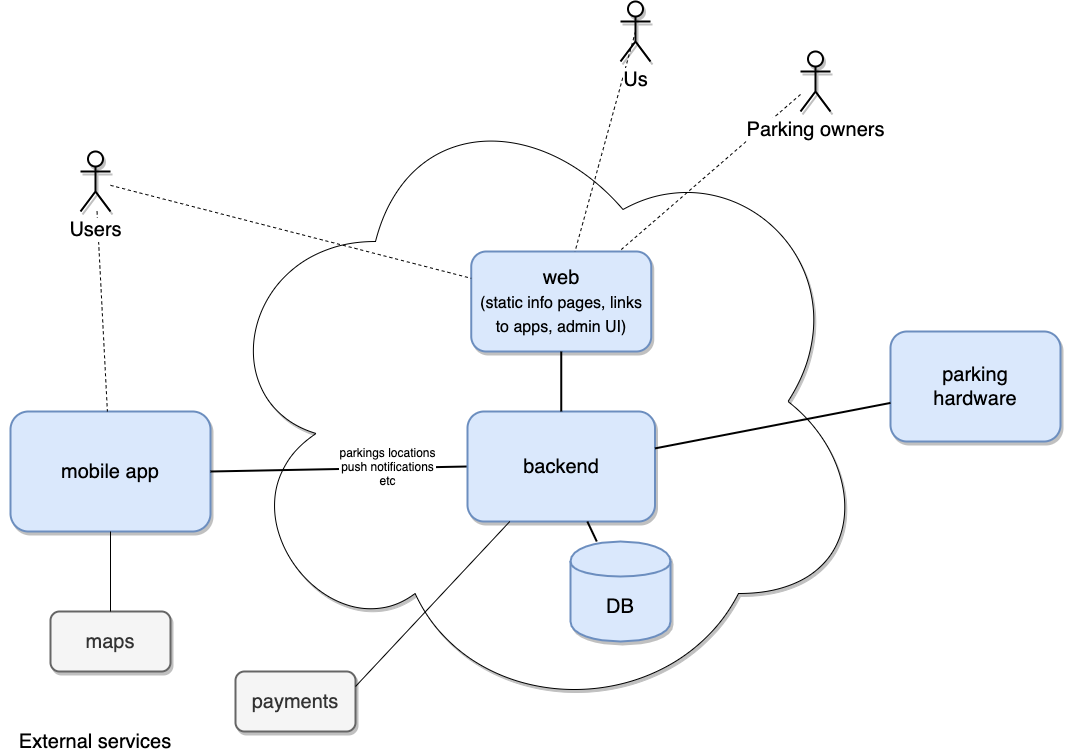
One step back, three steps front
Backend
Somehow we could easily agree on the backend technology for pilot - Python flask.
And a couple of our brave Devs developed Database schema and a REST API to CRUD all the entitites.
For future we discussed a possibility to rewrite some of the micro-services in Go for speed and scale.
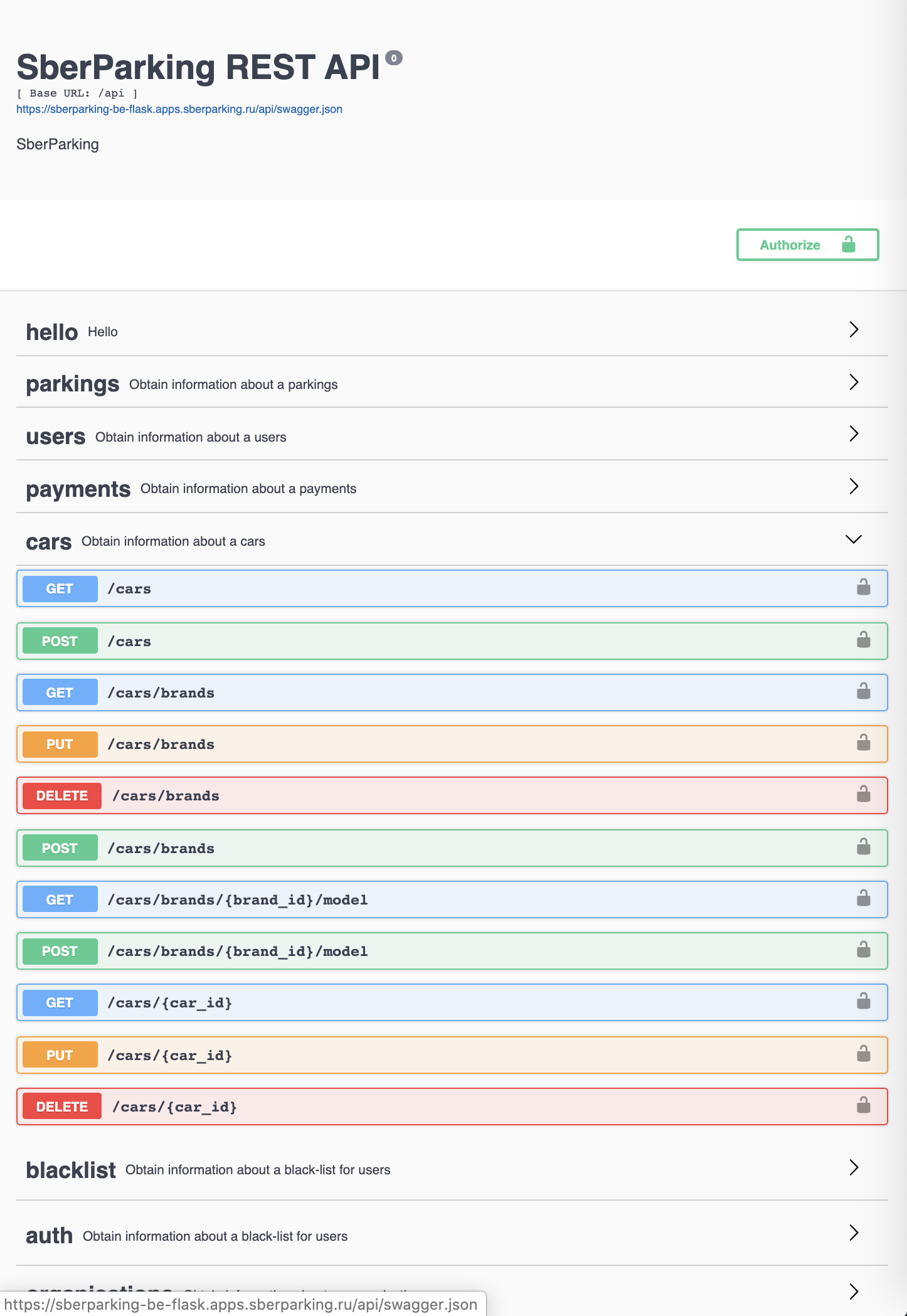
Frontend
This was and still is a challenge.
None of us truly possessed deep skills in web or mobile frontends.
So we ended up trying various ways:
- Python flask template
- Node.js
- React Native
We considered hiring external consultants\studio to outsource this work,
or at least give us recommendations which way to. But didn’t agree on that internally.
To the date we still have not decided, and in fact it became quite a stumbling point for our further progress.
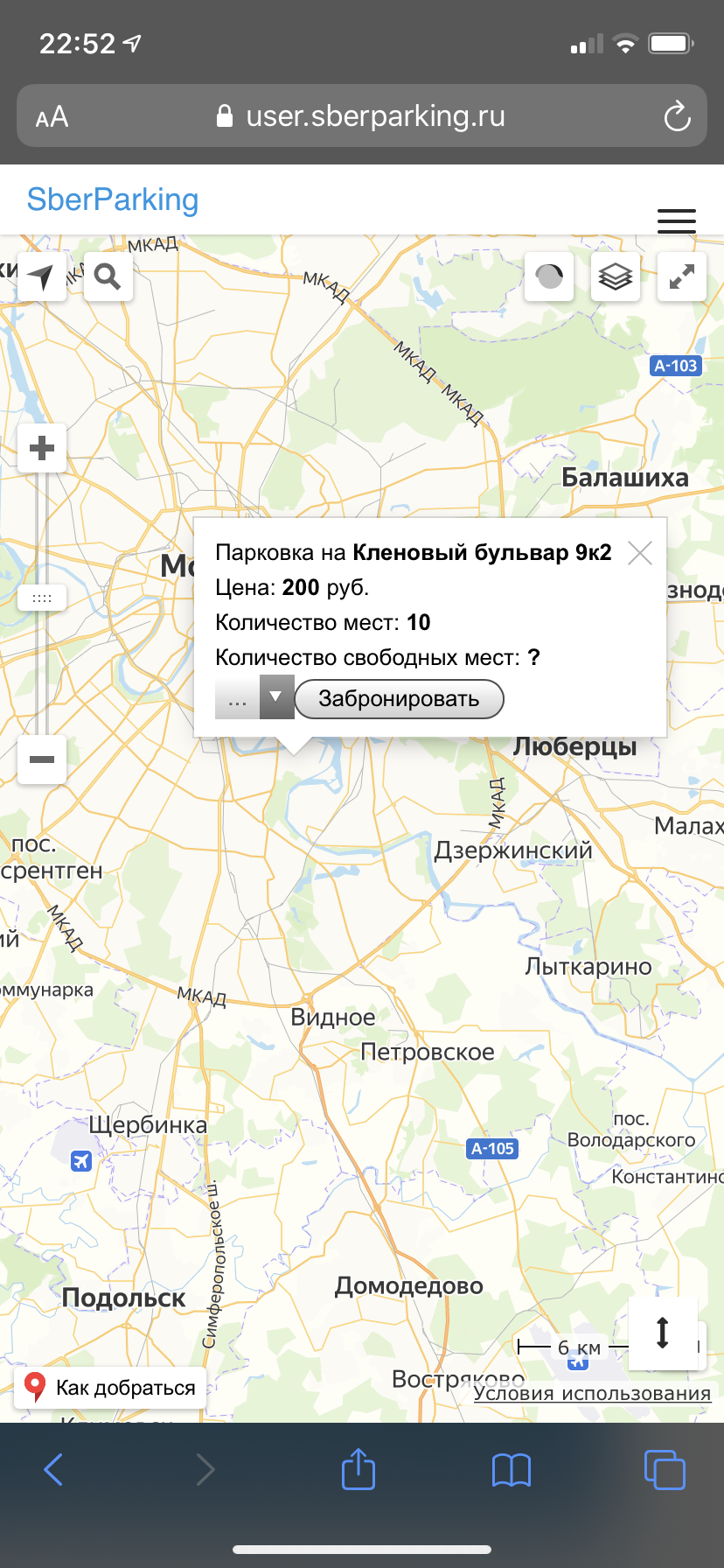
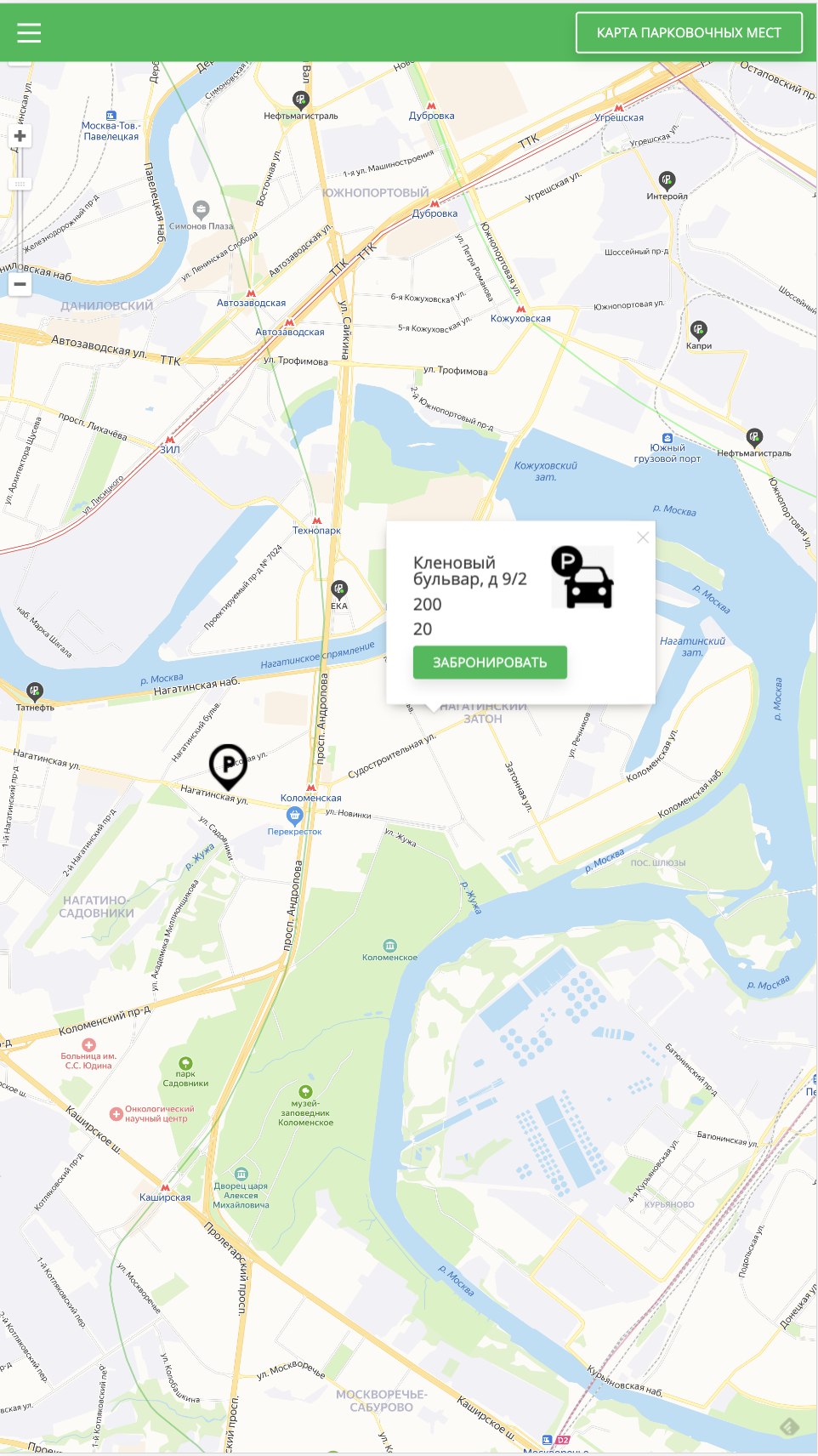
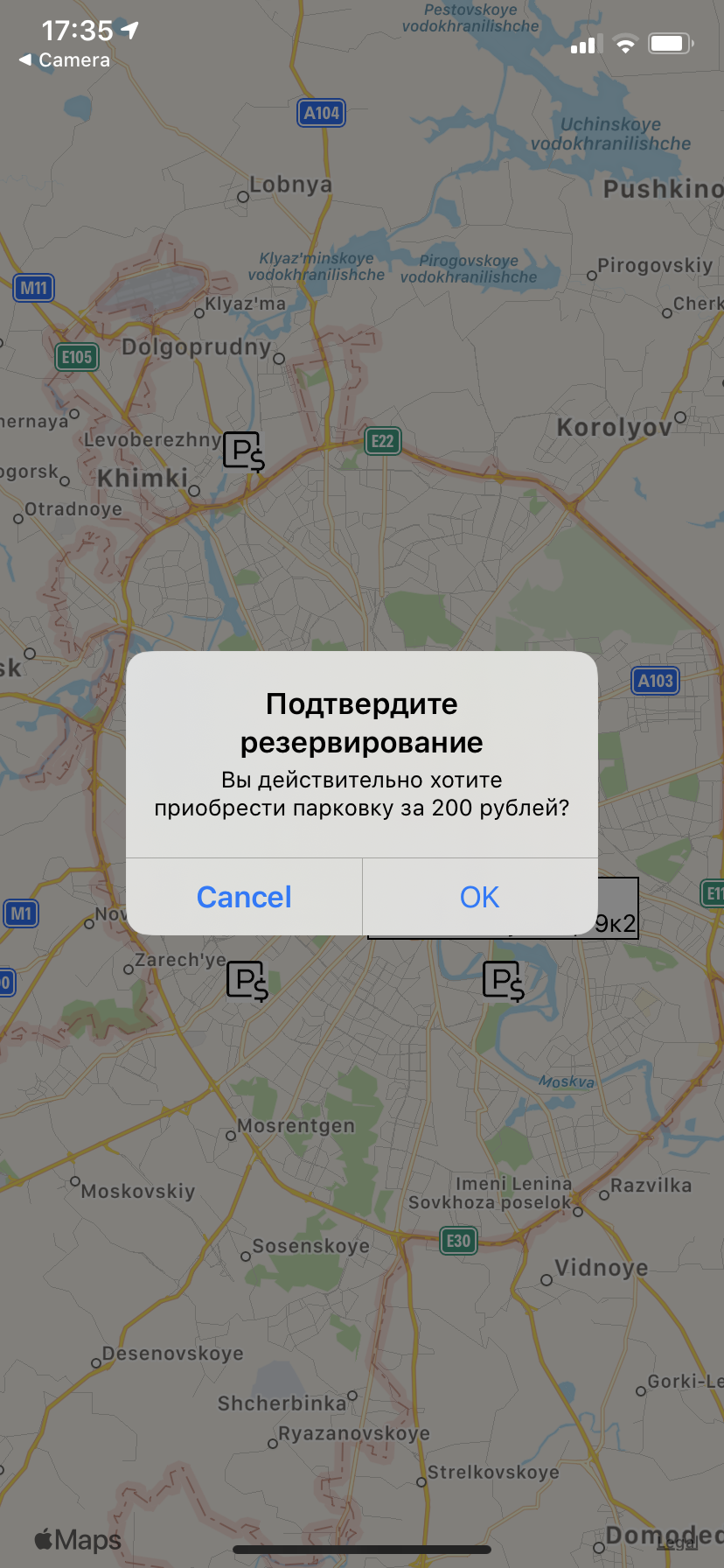
Process
One key insight for me personally was that people work much harder, when they are not paid.
It’s a long journey till we make any money, and people are free to do what they like.
It’s more like a hobby, but still with a common goal in front of us.
It’s a sensation of belonging to something big.
Plus the feeling of being able (“I can”) that gives more satisfaction that money.
Enthusiasm quickly builds up, and we find ourselves Zoom-meeting every evening, tired and exhausted by daily work, families and children. But instead of playing Quake like 20 years ago, we discuss boring spreadsheets and not working Python code.
Hustlers - go and meet every one and then with a tracker, a representative from the Accelerator.
Showing him pitch, financial spreadsheets, unit analysis, and at some point screenshots of something “almost working”.
Hackers - create 30 channels in Slack and 50 entities in Postgres.
Mentors - annoy everyone with millions of links to articles.
Stack
Here is a flat list of all the systems, tools and technologies that we used:
- WhatsApp - unstructured chat
- Slack - structured chat
- Zoom - daily meetings
- GitLab - code, CI/CD, Merge Requests, Issues, Milestones
- Python flask - backend
- React Native, Node.js, Python flask - frontend options
- Google Cloud Platform - for all infrastructure
- Kubernetes - to host apps, as GKE in GCP
- Postgres - for data, as Cloud SQL in GCP
- Terraform - declarative way to describe infrascture and drive provisioning and destruction
- Google Drive - shared folder for all file data
- StatusCake - uptime monitoring
Started using but didn’t stick: MongoDB, Confluence, Jira, Trello
DevOps
CI/CD
I’m a huge fan of Continuous Delivery, and when I see source code, I have a uncontrollable urge to build and deploy it somewhere. I love pipelines, and have used a dozen of CI/CD tools over almost 20 years, starting with CruiseControl, grand-dad of all Jenkins-es.
My favourite one these days is GitLab, which is not perfect but better than most.
I’ve used it on a last few roles, both hosted and self-hosted, configuring, automating and extending it with custom Python \ Go tools.
I open source some of my code in my group: https://gitlab.com/optimisen
So it’s a default choice for me these days when starting a new project,
especially with all the nice new features they introduced recently, like AutoDevOps.
TBH I was pretty skeptic when they started building AutoDevOps, but I grew on it.
And in this startup I’ve used AutoDevOps almost fully, customizing it via environment variables and some minimal amount of pipeline YAML.
For Merge Requests - we’ve used “review” environments with ephemeral PostgreSQL instances that it provides.
We automated some of the tests (black box via backend REST API) and run them in such “review” envs.
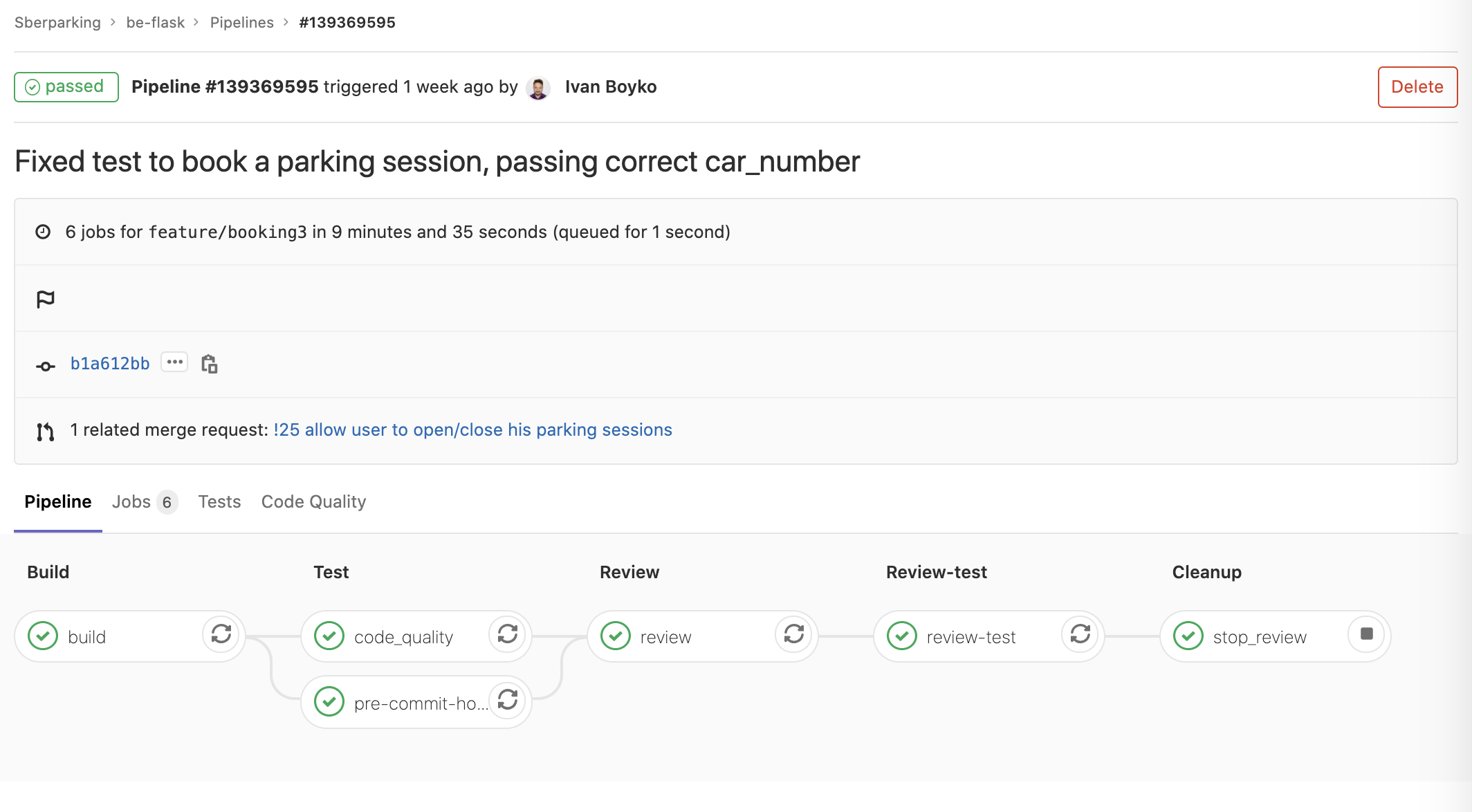
For master pipelines - we deployed to persistent Staging and Produciton environments, both with persistent databases in Google Cloud.
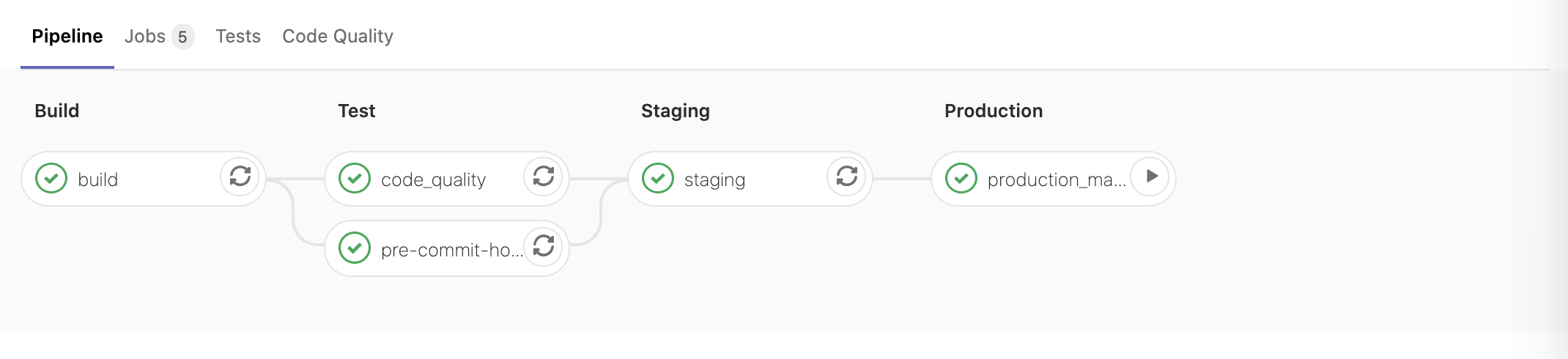
We all know Infrastructure as Code, and Pipeline as Code.
I thought I invented a new term - Pipeline for Infrastructure as Code, but turned out ThoughtWorks already coined it a few months ago. Damn ThoughtWorks, it’s the second time you undercut me! :)
For now we have just 1 infra environment really, but still it’s cool to drive infrastructure provisioning the same way as we do for applications:
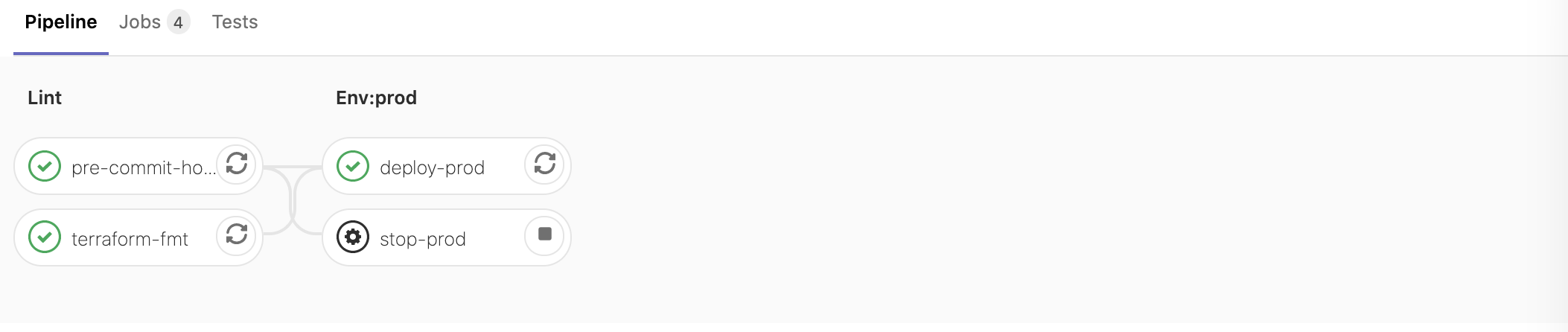
Kubernetes
There’s really no alternative these days to Kubernetes for running backend apps at scale.
But even being a CKA
it never stops amazing me with complexity.
Things like GitLab AutoDevOps really help to hide that complexity,
and get running fast. Ideally you still need to understand internals of Kubernetes, especially if you hit problems
and need to debug your pods, deployments etc. But it’s way simpler than authoring all Kubernetes, Helm, and delivery process yourself.
You can easily cherry-pick what you need from AutoDevOps.
As a bonus you get various pages in GitLab showing Kubernetes data like metrics, logs, even shell access into pods. Here is one example:
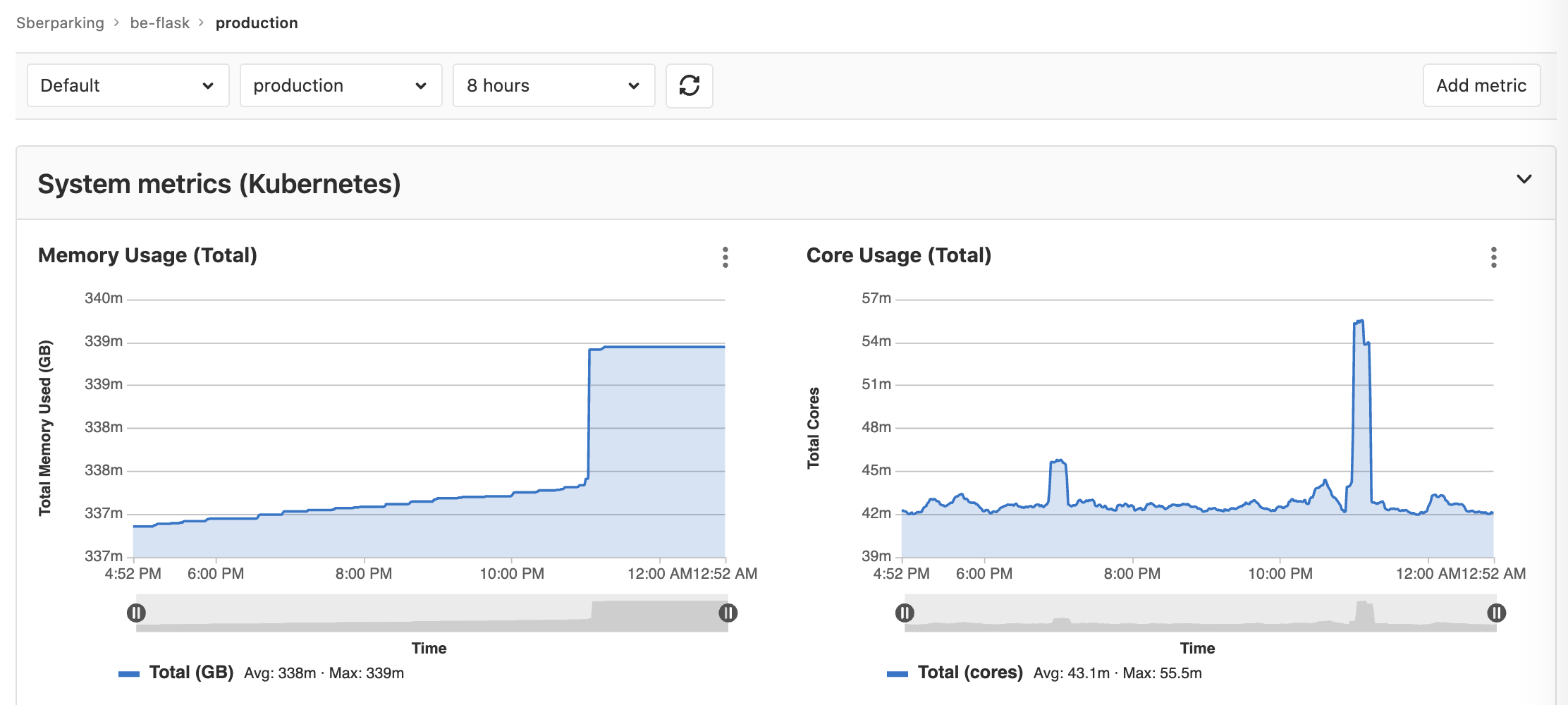
I’ve automated provisioning of Kubernetes cluster via Terraform and GitLab pipeline (see above and below about that), but adding cluster to GitLab is still manual, as well as clicking all the buttons to install: Helm Tiller, Nginx Ingress, Cert-Manager, Prometheus, GitLab Runner, etc.
We do use autoscaling on node level in GCP, but not yet HPA (Horizontal Pod Autoscaling).
Cloud
I chose Google Cloud.
Mainly because I was tired of AWS quirkiness, never trusted Azure and exhausted my DigitOcean credit.
I’ve heard that GCP has better support for Big Data and Kubernetes, and certainly confirmed the latter.
Things like autoscaling are built-in on the cloud level, while we wasted quite some time implementing it in AWS in the past.
GCP is generous - they give $300 free credit for 12 months.
And we’ve burnt most of it during the first month actively using:
- IAM
- VPC
- Cloud DNS
- Compute Engine
- Kubernetes Engine
- SQL
- Logging
- Error Reporting
I’ll be honest - I definitely enjoyed working with GCP.
Some bits felt like proper magic, for example Error Reporting showing exceptions from our Python code deployed to Kubernetes,
with zero efforts from our site. This helped for instance to quickly debug us hitting Lets Encrypt rate limits for TLS certificates.
I’ll definitely stick to GCP for further projects, and will probably look at certification with them at some point.
Terraform
For obvious reasons I cannot share our code, but here is an open-source example how infrastructure was defined in code: https://gitlab.com/optimisen/cloud/gcp/gcp-base/-/blob/master/main.tf
Some key aspects:
-
re-use existing modules, search in Terraform Registry, sort by number of downloads and authority of the author
-
use “staged” apply\destroy for modules, example, as they don’t support yet “depends_on” attribute, first - create low level VPC with subnets, then all the things that build on top of it
-
use Terraform Cloud to store “state” with locking, as a simpler and cleaner way than usual S3 \ DynamoDB approach and the likes of it
-
drive provisioning via GitLab pipeline as was shown on the screenshot above, see example of .gitlab-ci.yml which uses separately made Docker image optimisen/terraform-provisioner containing Terraform, AWS and GCP CLI tools, kubectl, helm etc
Conclusion
No idea what future holds for all of us.
Hopefully millions of pounds, maybe even via this startup.
But I can certainly say that we got priceless experience of building something together, and doing it under time pressure.
It’s an amazing freedom to work on a Green Field project, to use the best modern tools and systems,
and to practice your GyShiDo skills in a team of like-minded people.
May the source be with you!
Have a great day!